English
English Deutsch
Deutsch Čeština
Čeština Ελληνικά
Ελληνικά Italiano
Italiano Svenska
Svenska
Chasse au trésor GFP
Introduction
Cette chasse au trésor a été conçue pour initier les participants à diverses approches en bio-informatique pouvant être utilisées pour identifier et analyser les séquences d’ADN et de protéines. Dans cette activité, nous allons analyser la séquence de l’ADN et des acides aminés de la protéine à fluorescence verte (GFP) et des molécules qui y sont étroitement liées, en utilisant différentes bases de données et autres outils Web. Des données biologiques – par ex., des séquences d’ADN et de protéines ou des informations sur les structures – sont conservées et préservées dans des bases de données qui sont accessibles aux scientifiques. Étant donné que la plupart des bases de données sont élaborées grâce à des fonds publics, elles sont aussi accessibles au grand public. De la même façon, les outils bio-informatiques sont conçus par des scientifiques qui reçoivent des subventions du secteur public et ils sont donc mis à la disposition d’autres scientifiques et du public. Dans cette activité, nous utiliserons ces types de bases de données et d’outils bio-informatiques pour effectuer nos analyses.
Les pré-requis techniques
L’application de visualisation Astex requiert l’installation de Java sur votre ordinateur et doit bénéficier des paramètres d’autorisation de votre navigateur Web. Vous pouvez installer Java gratuitement à partir de java.com. Cliquez sur le lien suivant pour voir la procédure à suivre afin d’activer Java sur votre navigateur Web.
Outils bioinformatiques
Registre Européen des nucléotides, ENA (European Nucleotide Archive) https://www.ebi.ac.uk/ena/browser/sequence-search
Une base de données qui offre des dossiers complets d’information sur la détermination mondiale des séquences nucléotidiques, couvrant les données de séquençage brut, des informations sur l’assemblage des séquences génomiques et des annotations fonctionnelles. L’ENA est constitué d’un nombre distinct de bases de données qui comprennent la banque du Laboratoire Européen de biologie moléculaire (LEBM), la Sequence Read Archive (SRA) et la Trace Archive.
MUSCLE (anglais : Multiple Sequence Comparison by Log-Expectation) http://www.ebi.ac.uk/Tools/msa/muscle/
Un outil pour aligner et comparer des séquences multiples, particulièrement utile pour les séquences d’acides aminés.
EMBOSS Transeq (de l’anglais : European Molecular Biology Open Software Suite Transeq) http://www.ebi.ac.uk/Tools/st/emboss_transeq/
Un outil qui traduit les séquences d’acides nucléiques vers les séquences peptidiques correspondantes.
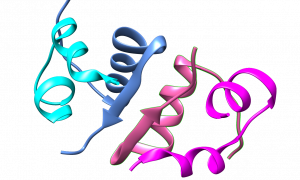
Protein Data Bank en Europe (PDBe) http://www.ebi.ac.uk/pdbe/
Une base de données qui contient des informations sur la structure des macromolécules biologiques.
Navigation d’activité
Le menu de navigation ci-dessous indique les étapes individuelles pour la réalisation de l’activité. Vous pouvez débuter la chasse au trésor en cliquant sur “Introduction, chasse au trésor GFP” dans le menu ci-dessous.

Topic area: Bioinformatics
Age group: 16-19
Author: Philipp Gebhardt
Share: