Čeština
Čeština Français
Français Ελληνικά
Ελληνικά Italiano
Italiano Svenska
Svenska
Step 3: Translation of mRNAs
Overview
In this part of the activity, we will translate the mRNA sequences of the four fluorescent proteins into amino acid sequences. To do this, we will be using a tool called EMBOSS Transeq (European Molecular Biology Open Software Suite Transeq). This web-based tool simulates the translation of mRNA sequences into a sequence of amino acids in the one-letter code.
Your task
Proceed as described below:
- Go to the tab “Sequence 1” and copy the whole mRNA sequence which starts with >Sequence1 (shortcut Ctrl.+C).
- Paste the nucleotide sequence into the EMBOSS Trranseq search box (shortcut Ctrl. + V).
- Follow the instructions in the “EMBOSS Transeq” tab to translate your sequence.
- Have a look at your protein and try to answer the questions in the “Questions” tab.
- Repeat the same procedure for all of the 4 sequences.
EMBOSS Transeq
- Go to the tab “Sequence 1” and copy the whole mRNA sequence which starts with >Sequence1 (shortcut Ctrl.+C).
- Paste the nucleotide sequence into the EMBOSS Trranseq search box (shortcut Ctrl. + V).
- Leave all other settings as they are.
- Just click on the large “Submit” button and your sequence will be translated.
- You will see the results after a few seconds.
- Have a look at your protein and try to answer the questions in the “Questions” tab.
- Repeat the same procedure for all of the 4 sequences.
Sequences 1-4
Sequence 1
>Sequence1_AVGFP
ATGAGTAAAGGAGAAGAACTTTTCACTGGAGTGGTCCCAGTTCTTGTTGAATTAGATGGCGATGTTAATGGGCAAAAATTCTCTGTCAGTGGAGAGGGTGAAGGTGATGCAACATACGGAAAACTTACCCTTAATTTTATTTGCACTACTGGGAAGCTACCTGTTCCATGGCCAACACTTGTCACTACTTTCTCTTATGGTGTTCAATGCTTCTCAAGATACCCAGATCATATGAAACAGCATGACTTTTTCAAGAGTGCCATGCCCGAAGGTTATGTACAGGAAAGAACTATATTTTACAAAGATGACGGGAACTACAAGACACGTGCTGAAGTCAAGTTTGAAGGTGATACCCTTGTTAATAGAATCGAGTTAAAAGGTATTGATTTTAAAGAAGATGGAAACATTCTTGGACACAAAATGGAATACAACTATAACTCACATAATGTATACATCATGGGAGACAAACCAAAGAATGGCATCAAAGTTAACTTCAAAATTAGACACAACATTAAAGATGGAAGCGTTCAATTAGCAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTCCACACAATCTGCCCTTTCCAAAGATCCCAACGAAAAGAGAGATCACATGATCCTTCTTGAGTTTGTAACAGCTGCTAGGATTACACATGGCATGGATGAACTATACAAA
Sequence 2
>Sequence2_GFPm
ATGTCTAAAGGTGAAGAATTATTCACTGGTGTTGTCCCAATTTTGGTTGAATTAGATGGTGATGTTAATGGTCACAAATTTTCTGTCTCCGGTGAAGGTGAAGGTGATGCTACTTACGGTAAATTGACCTTAAAATTTATTTGTACTACTGGTAAATTGCCAGTTCCATGGCCAACCTTAGTCACTACTTTCGGTTATGGTGTTCAATGTTTTGCTAGATACCCAGATCATATGAAACAACATGACTTTTTCAAGTCTGCCATGCCAGAAGGTTATGTTCAAGAAAGAACTATTTTTTTCAAAGATGACGGTAACTACAAGACCAGAGCTGAAGTCAAGTTTGAAGGTGATACCTTAGTTAATAGAATCGAATTAAAAGGTATTGATTTTAAAGAAGATGGTAACATTTTAGGTCACAAATTGGAATACAACTATAACTCTCACAATGTTTACATCATGGCTGACAAACAAAAGAATGGTATCAAAGTTAACTTCAAAATTAGACACAACATTGAAGATGGTTCTGTTCAATTAGCTGACCATTATCAACAAAATACTCCAATTGGTGATGGTCCAGTCTTGTTACCAGACAACCATTACTTATCCACTCAATCTGCCTTATCCAAAGATCCAAACGAAAAGAGAGACCACATGGTCTTGTTAGAATTTGTTACTGCTGCTGGTATTACCCATGGTATGGATGAATTGTACAAATAACTGCAG
Sequence 3
>Sequence3_YFP
AATATTTTTATTAATTCATTAGAAAAATGAGAGGAAGGATTATTATGTTTAAAGGTATAGTAGAAGGTATAGGAATCATTGAAAAAATTGATATATATACTGACCTAGATAAGTATGCAATTCGATTTCCTGAAAATATGTTGAATGGAATTAAAAAGGAGTCGTCAATAATGTTTAACGGATGCTTCTTAACGGTAACTAGCGTGAATTCAAACATTGTCTGGTTTGATATATTTGAAAAAGAAGCACGTAAGCTTGATACTTTTCGGGAATATAAGGTAGGTGACCGAGTAAATTTAGGAACATTCCCAAAATTTGGCGCTGCATCTGGTGGGCATATATTATCAGCAAGGATTTCATGTGTAGCAAGTATTATTGAAATAATAGAAAATGAGGATTATCAACAAATGTGGATTCAAATTCCTGAAAATTTTACAGAGTTTCTTATTGATAAAGACTATATTGCTGTGGATGGTATTAGCTTAACTATTGACACTATAAAAAACAACCAATTTTTCATTAGTTTACCCTTAAAAATAGCACAAAATACAAATATGAAATGGCGAAAAAAAGGTGATAAGGTAAATGTTGAGTTATCAAACAAAATTAATGCTAACCAGTGTTGGTAATTTACTGAGGATAGTAAAAATGAACTGTTTAAAATAATATTTAAATTTTTATTTATAATACAGAGTCAGTTGTTGTAAATAGTCTGAGTGGTAAATAAGTTCTACCATTAATTAAATATTATCCATATTAAATAAAGGATCT
Sequence 4
>Sequence4_RFP
AGTTTCAGCCAGTGACAGGGTGAGCTGCCAGGTATTCTAACAAGATGAGTTGTTCCAAGAATGTGATCAAGGAGTTCATGAGGTTCAAGGTTCGTATGGAAGGAACGGTCAATGGGCACGAGTTTGAAATAAAAGGCGAAGGTGAAGGGAGGCCTTACGAAGGTCACTGTTCCGTAAAGCTTATGGTAACCAAGGGTGGACCTTTGCCATTTGCTTTTGATATTTTGTCACCACAATTTCAGTATGGAAGCAAGGTATATGTCAAACACCCTGCCGACATACCAGACTATAAAAAGCTGTCATTTCCTGAGGGATTTAAATGGGAAAGGGTCATGAACTTTGAAGACGGTGGCGTGGTTACTGTATCCCAAGATTCCAGTTTGAAAGACGGCTGTTTCATCTACGAGGTCAAGTTCATTGGGGTGAACTTTCCTTCTGATGGACCTGTTATGCAGAGGAGGACACGGGGCTGGGAAGCCAGCTCTGAGCGTTTGTATCCTCGTGATGGGGTGCTGAAAGGAGACATCCATATGGCTCTGAGGCTGGAAGGAGGCGGCCATTACCTCGTTGAATTCAAAAGTATTTACATGGTAAAGAAGCCTTCAGTGCAGTTGCCAGGCTACTATTATGTTGACTCCAAACTGGATATGACGAGCCACAACGAAGATTACACAGTCGTTGAGCAGTATGAAAAAACCCAGGGACGCCACCATCCGTTCATTAAGCCTCTGCAGTGAACTCGGCTCAGTCATGGATTAGCGGTAATGGCCACAAAAGGCACGATGATCGTTTTTTAGGAATGCAGCCAAAAATTGAAGGTTATGACAGTAGAAATACAAGCAACAGGCTTTGCTTATTAAACATGTAATTGAAAAC
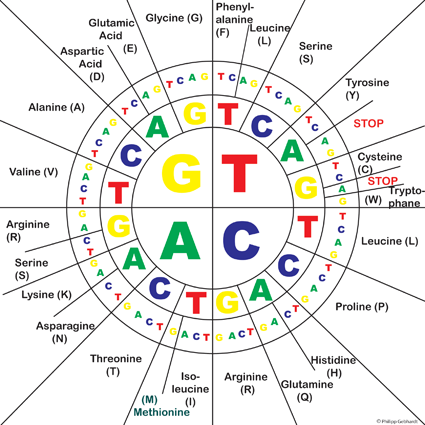
Codon sun
Questions
- How is a DNA sequence translated into an amino acid sequence? Describe the single steps. Use the codon sun in the “Codon sun” tab, if you would like to.
- How can you find the “right” open reading frame?
- In the EMBOSS Transeq output, what do you think the symbol * (asterisk) stands for?
Activity navigation
Share: