Proteomics: a different lens for precision medicine
The dynamic world of proteomics is shaping the future of personalised medicine, but some obstacles stand in the way
Credit: Isabel Romero Calvo/EMBL, edited by Karen Arnott/EMBl-EBI
If the genome is the blueprint for building an organism, the proteome is the construction crew along with some of the working materials. Each protein plays a role in constructing and maintaining the organism’s biological structures. By studying all the proteins in an organism, proteomics helps us understand health and disease. It’s also a key discipline for making precision medicine a reality.
So why has proteomics so far been overshadowed by other fields, including genomics, and how is EMBL driving the discipline forward?
What is proteomics?
The proteome is made up of all the proteins that exist in an organism at any given moment. Unlike the genome, which is relatively fixed throughout the course of an organism’s life, the proteome is extremely dynamic – it changes over time and depending on physiological conditions.
Proteomics uses high-throughput techniques, which perform rapid and simultaneous processing of a large number of experiments. Until the early 2000s, scientists were limited to observing a small number of proteins at a time. But the advent of mass spectrometry, in particular, has meant they can now see thousands of proteins simultaneously across dozens or even hundreds of samples. This has been a real step change, as has been the wider sharing of proteomics data.
Clinical applications of proteomics
Proteins are the workhorses of the cell and most biological functions rely on them. They are also a good way to study phenotypes – an organism’s features. Proteins provide a complementary ledger of information alongside genomics or transcriptomics.
“If we want to understand how life works, what makes us ill, and what can help us get better, looking at the blueprint of the genome is not enough. We need different data types, and better ways of integrating them.”
An important application of proteomics in the clinical world is the search for biomarkers – molecules or characteristics in the body that researchers measure to provide a snapshot of health. Biomarkers are also used as an indicator for a person’s risk of developing a certain disease or for how likely they are to respond to a treatment. For instance, C-reactive protein (CRP) is a biomarker for inflammation, and measuring the blood levels of CRP helps clinicians assess conditions like infections, autoimmune diseases, and cardiovascular disease risk.
Proteomics experiments can measure levels of proteins in different physiological conditions and draw out useful biomarkers for a range of illnesses, including cancer and autoimmune diseases. For example, protein-protein signalling deregulation can lead to cancer, while protein aggregation can play a role in neurological diseases. Proteomics provides a useful lens through which researchers can detect how disease sets in at a molecular level. It also uncovers additional insights for developing new clinical interventions.
What is precision medicine?
Precision medicine, sometimes called personalised medicine, is an emerging healthcare approach which takes into account an individual’s genetics, molecular profile, environment and lifestyle to predict what treatment would work best for them.
Driving technological innovation
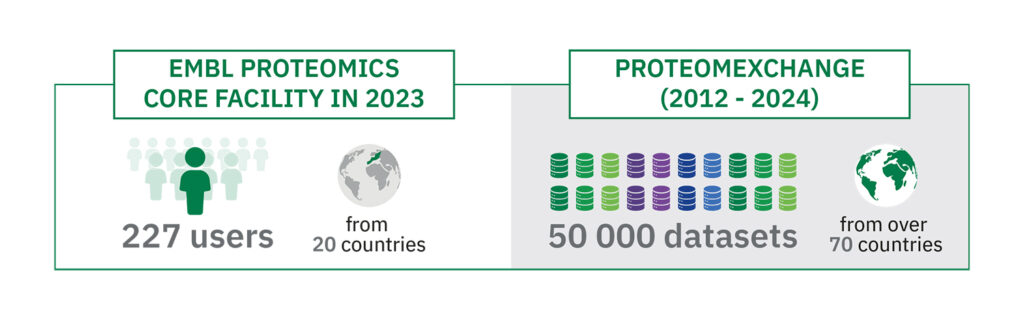
Observing this ever-changing “construction team” in our cells is no easy task. Proteomics uses a wide range of highly complex technologies, many of which are available to scientists worldwide through EMBL’s Proteomics Core Facility, which supports over 700 scientific projects every year.
“Over 200 scientists from institutes in 20 countries ran experiments at EMBL’s Proteomics Core Facility in 2023,” said Mandy Rettel, Operational Manager at EMBL’s Proteomics Core Facility. “Alongside state-of-the-art mass spectrometry equipment and world-leading expertise, what makes this facility unique is that it’s deeply embedded in the EMBL scientific environment.”
This in itself adds value. For example, a recent cross-EMBL collaboration brought together expertise in computational and experimental biology, machine learning, and data wrangling to shed light on a decades-old question. Protein phosphorylation is a process that can alter the structure of a protein, activating it, deactivating it, or modifying its function. Despite decades of work, the number of phosphorylation sites and knowledge about which ones are critical for life remain a mystery. In a collaboration that spanned three of the six EMBL sites, scientists developed the largest resource to date for identifying functionally relevant phosphosites. This has enormous potential to improve our understanding of biological processes and disease.
“Over 200 scientists from institutes in 20 countries ran experiments at EMBL’s Proteomics Core Facility in 2023.”
“Although proteomics equipment and instruments are becoming increasingly easier to use, they are still very complex in terms of the physical processes happening inside,” explained Mikhail Savitski, Head of the EMBL Proteomics Core Facility and Research Team Leader. “As with all multiomics data, proteomics is difficult to understand, so we put a lot of effort into making the data easy to digest and access by our users. And then, of course, there is the data sharing side, which comes with its own challenges.”
Opening up the data
The value of scientific data lies at least partly in its reuse. By making data openly accessible, researchers enable others to re-analyse them, ask new research questions, and gain new knowledge.
“Proteomics is completely different now compared to when I started my PhD,” said Savitski. “Back then, nobody was sharing data outside their lab, but now my group reprocesses data from other publications and often extracts insights that were previously unknown. Nobody is perfect, and when you publish data, you can’t extract everything of value from them, so it’s important for the community to be able to mine the data further.
“None of this would be possible without PRIDE and the ProteomeXchange, which facilitate data sharing and access worldwide. In my view, EMBL-EBI’s PRIDE data resource has been a real game-changer for proteomics and has brought the field to maturity.”
Making data sharing common practice
As proteomics technology has improved in speed and throughput, the volumes of data have also increased. Data sharing has become the norm in proteomics due to a number of factors. Firstly, proteomics is increasingly seen as important to life science data ecosystems. “Researchers are realising more and more that while genomics gives you the blueprint, you need other data types to understand what is going on with the biology,” said Rettel.
Secondly, reliable data repositories are now available, enabling better proteomics data access and reuse. And finally, journals and funding agencies are pushing researchers to share their data. “Nowadays, it would be unthinkable to publish a proteomics paper in a top journal without making the data available, which is good news for open science,” explained Savitski.
Data deluge – sink or swim
Over the last decade, EMBL’s European Bioinformatics Institute (EMBL-EBI) has seen the volumes of proteomics data generated by the scientific community skyrocket. “If anyone would have told me that we would reach 50,000 proteomics datasets in less than 12 years, I would have said they were crazy,” beamed Juan Antonio Vizcaíno, Team Leader at EMBL-EBI.
EMBL-EBI’s proteomics data resource called PRIDE was set up in 2004, at a time when additional information about the data from proteomics experiments was confined to the supplementary materials sections of scientific papers. Back then, there was no way to verify the claims in an article about proteomics because there was no public repository for the data, meaning experiments couldn’t be replicated or verified.
It took a few years for PRIDE to mature. A major shift took place in 2012, when EMBL-EBI and collaborators set up the ProteomeXchange consortium – an international collaboration for resources that store and disseminate protein data. This was an effort to avoid duplication and make proteomics data easier to access and reanalyse. ProteomeXchange is similar in concept to the Worldwide Protein Data Bank for protein structures or the International Nucleotide Database Consortium for nucleotide data. One key difference, however, is that in ProteomeXchange, the data are not replicated across the different member resources.
“EMBL-EBI’s PRIDE data resource has been a real game-changer for proteomics and has brought the field to maturity.”
At the time of writing, the ProteomeXchange consortium has six members: PRIDE in Europe, PeptideAtlas, MassIVE and PanoramaView in the US, iProX in China and JPOST in Japan. PRIDE is the largest of these resources, hosting approximately 80% of the submitted datasets, but this may shift in the coming years, as Asian countries increasingly take up data-sharing practices and mature their own resources.
“When we started ProteomeXchange, the number of proteomics datasets in the public domain was very small, plus they were not standardised and there was generally little appetite for data sharing among researchers,” remembered Vizcaíno. “So we tried to encourage scientists to share data by making the submission process as straightforward as possible. The fact that in 2023, we reached over 50,000 datasets is remarkable given where we started. It’s impressive to step back and look at the increase in the speed at which data is generated and shared. To give you an idea, it took the community five years to generate and share the first 10,000 datasets, and just over a year to get the most recent 10,000 datasets. That is a staggering increase!”
The geographic spread of the data submissions and downloads is also impressive, with datasets coming to PRIDE from over 70 countries, and ProteomeXchange resources being cited by thousands of scientific papers each year. Even more significantly, data reuse activities continue to grow in the field, involving artificial intelligence (AI) methods, metaanalysis studies, proteogenomics applications, and the development of novel analysis software, among many other applications.
Public proteomics data management is a team sport
Openly sharing proteomics data is not always straightforward due to their volume and complexity. Sometimes data submitters require support from the PRIDE team, which only has nine staff members. The team size hasn’t changed much over the years, despite the increasing volumes of data they wrangle. They have managed to keep up by automating the submission process whenever possible, although some manual intervention is still required at times.
Made up of bioinformaticians, biologists, and software developers, the PRIDE team doesn’t just manage data submissions. They also provide training for researchers who want to submit or leverage proteomics data. The team also reanalyses public proteomics datasets and disseminates them to other EMBL-EBI resources, including UniProt and Expression Atlas, to make the proteomics data easier to find and use by scientists from different fields.
But nine people cannot manage the world’s proteomics data, so a big priority for the team is collaborating with other institutes and experts, including ProteomeXchange, the Proteomics Standards Initiative, and the ELIXIR’s Proteomics Community.
What is next for proteomics data infrastructure?
Alongside improved access to proteomics technology and the growing appetite for data sharing, proteomics also requires robust and sustained funding. Together, these factors will enable experimental and data infrastructures to support the discovery of new insights that can help us understand life, health, and disease better.
“It’s easy to take research infrastructures for granted and expect they will always be there, but the truth is that they require continuous funding, expertise, and community support,” said Savitski.
Proteomics continues to change at a rapid pace. The public availability of proteomics data makes it a prolific field for developing and training new AI methods, which are already helping to analyse more data to gain new insights that could be useful for precision medicine and beyond.
Another development on the horizon is the increasing amount of ‘human sensitive proteomics data’ (also as part of multiomics studies), meaning data that can’t be made openly available due to legal and ethical reasons. This requires a different type of data infrastructure, which is currently in development at EMBL-EBI. “We’re hoping to have something to present to the community towards the end of 2025,” explained Vizcaino. “This is a crucial next step for leveraging proteomics data to guide precision medicine.”
“Not all datasets are created equal,” said Vizcaíno. “But it’s gratifying to see proteomics coming into the spotlight, alongside genomics and bioimaging. If we want to understand how life works, what makes us ill, and what can help us get better, looking at the blueprint of the genome is not enough. We need different data types, and better ways of integrating them to extract knowledge and understand life in context.”